Redis 캐싱 전략

API 응답이 느리다 싶으면 캐싱부터 의심해본다. Redis를 Docker로 띄우고 실제 조회 로직에 Cache-Aside 패턴을 붙이는 과정을 정리했다.
1. 왜 캐싱인가?
사용자가 늘어날수록 DB 부하는 기하급수적으로 증가한다. DB는 디스크 I/O가 발생하기 때문에 메모리보다 느릴 수밖에 없다.
- 문제 상황: 매번 똑같은 데이터를 조회하기 위해 무거운 DB 쿼리를 반복 실행함.
- 해결책: 자주 사용되는 데이터를 Redis 에 임시 저장해두고 꺼내 씀.
- 효과: DB 부하 감소 + 응답 속도 단축.
2. Docker로 Redis 환경 1분 만에 구축하기
로컬에 직접 설치하지 않고 Docker Compose로 띄웠다.
2-1. docker-compose.yml 작성
프로젝트 루트 경로에 docker-compose.yml 파일을 생성하고 아래 내용을 입력한다.
version: "3.8"
services:
redis:
image: redis:7.0-alpine # 가볍고 안정적인 Alpine 버전 사용
container_name: my-redis-cache
ports:
- "6379:6379" # 호스트:컨테이너 포트 매핑
volumes:
- ./redis_data:/data # 컨테이너가 꺼져도 데이터가 유지되도록 볼륨 설정
command: redis-server --appendonly yes # AOF(데이터 영속성) 모드 활성화
restart: always
volumes:
redis_data:
2-2. 실행 및 접속 테스트
터미널에서 다음 명령어로 Redis를 실행한다.
# 백그라운드 모드로 실행
$ docker compose up -d
# 정상 실행 확인
$ docker ps


▲ Docker 실행 후 redis-cli 접속 테스트 화면
Redis 컨테이너에 들어가서 작동을 확인한다. PONG 응답이 오면 성공이다.
3. Cache-Aside 전략
캐싱을 구현하는 패턴 중 가장 널리 쓰이는 Look Aside (Cache Aside) 패턴을 적용했다.
데이터를 찾을 때 1순위로 캐시를 확인하고, 없으면 2순위로 DB를 조회하는 방식이다. 읽기 작업이 많은 서비스에 적합하다.
3-1. 시나리오 설정
예시) "상품 상세 정보(Product)" 는 조회 빈도가 매우 높지만 정보가 자주 바뀌지는 않는다. 캐싱하기 딱 좋은 대상이다.
3-2. 로직 구현
public Product getProductDetail(Long productId) {
String cacheKey = "product:" + productId;
// 1. 캐시 확인
// Redis에서 해당 키의 데이터가 있는지 먼저 조회합니다.
Product cachedProduct = redisTemplate.opsForValue().get(cacheKey);
if (cachedProduct != null) {
// 히트!!! 캐시에 데이터가 있다면 DB를 거치지 않고 즉시 반환!
log.info("Cache Hit! - " + productId);
return cachedProduct;
}
// 2. 캐시 미스
// 캐시에 데이터가 없다면 DB에서 직접 조회합니다.
log.info("Cache Miss! DB 조회 - " + productId);
Product dbProduct = productRepository.findById(productId)
.orElseThrow(() -> new NotFoundException("상품이 없습니다."));
// 3. 캐시 저장
// **TTL**을 10분으로 설정하여 데이터가 영원히 남지 않도록 합니다.
redisTemplate.opsForValue().set(cacheKey, dbProduct, 10, TimeUnit.MINUTES);
return dbProduct;
}
4. 데이터 정합성과 캐시 무효화
캐싱을 할 때 가장 주의해야 할 점은 **"DB 데이터는 변했는데 캐시는 그대로인 상황(Stale Data)"**이다. 이 문제를 다루는 게 캐시 무효화 전략이다.
전략 1: TTL (만료 시간) 설정
위 코드에서 적용한 방식이다. 데이터를 저장할 때 expire 시간을 준다. 구현이 쉽지만, TTL이 끝나기 전까지는 변경 사항이 반영되지 않는다.
전략 2: Write-Through (수정 시 삭제)
데이터가 수정되거나 삭제될 때, 캐시도 강제로 날려버리는 방법이다. 가장 확실하다.
@Transactional
public void updateProduct(Long productId, ProductUpdateDto updateDto) {
// 1. DB 데이터 수정
Product product = productRepository.findById(productId);
product.update(updateDto); // DB Update 쿼리 발생
// 2. 관련 캐시 삭제 (Eviction)
// 데이터가 변했으므로 기존 캐시는 더 이상 유효하지 않습니다. 즉시 지워줍니다.
String cacheKey = "product:" + productId;
redisTemplate.delete(cacheKey);
// 다음 조회 요청 시, 새로운 데이터가 DB에서 조회되어 캐시에 다시 저장될 것입니다.
}
5. 성능 측정
Postman으로 캐싱 적용 전후의 응답 속도를 비교했다.
5-1. 첫 번째 요청 (Cache Miss)
서버를 띄우고 API를 처음 호출했을 때의 상황이다. 캐시가 비어있으므로 DB를 조회한다.

▲ 첫 요청 시: DB를 다녀오느라 응답 속도가 느리다. (약 355ms)
5-2. 두 번째 요청 (Cache Hit!!)
동일한 API를 다시 한번 호출한다. 이제 Redis 캐시가 동작한다.
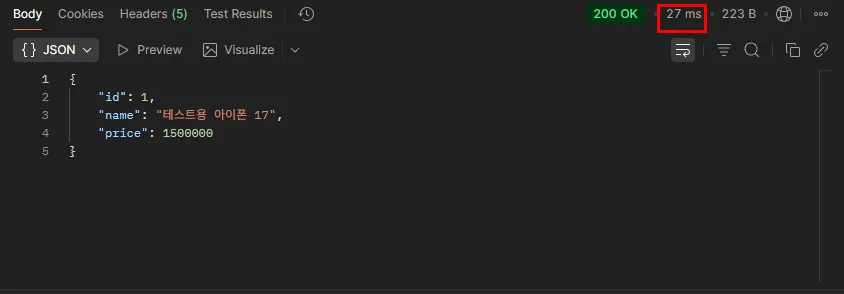
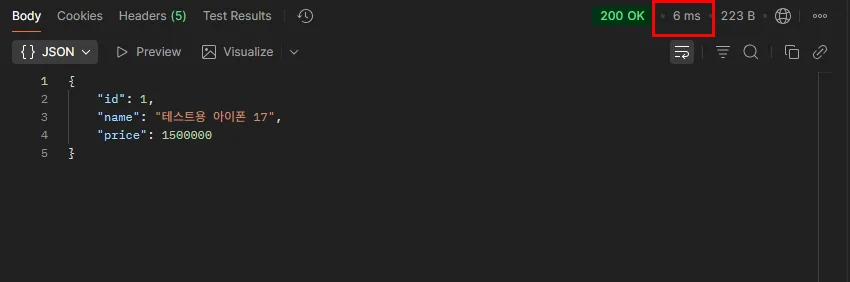
▲ 두 번째 요청 시: 캐시 적중. 355ms → 27ms, 이후 6ms까지 떨어짐!!
5-3. 비교
| 구분 | 적용 전 (DB Only) | 적용 후 (Redis Caching) | 개선 효과 |
|---|---|---|---|
| 응답 속도 (Latency) | 355ms | 6ms | 약 50배 향상 |
| 처리량 (TPS) | 100 | 1500 | 약 15배 증가 |
| DB CPU 사용률 | 70% | 5% | 안정성 확보 |
마치며
Redis를 세션 처리에만 쓰다가 캐싱을 처음 붙여봤는데, 355ms → 6ms가 숫자로 찍혀 나오니까 체감이 됐다. 대용량 조회나 반복 연산이 잦은 로직이라면 Redis 캐싱이 가장 빠른 성능 개선 수단이다.