ELK 파이프라인

로그 데이터를 RDBMS에 쌓으면 검색이 느리고 불편하다. 특정 에러 메시지가 들어간 로그를 찾으려고 LIKE '%keyword%' 쿼리를 돌리면 데이터가 쌓일수록 감당이 안 된다. ELK 스택을 직접 구성해보면서 개념을 정리했다.
1. Elasticsearch
1-1. RDBMS와는 다른 'Schemaless'
Elasticsearch는 RDBMS와 달리 Schema-less(스키마리스) 구조다.
- JSON 기반: HTTP 프로토콜과 JSON 데이터 기반으로 동작한다.
- 유연성:
test테이블에id컬럼만 있다가 갑자기nickname컬럼이 포함된 데이터가 들어와도, ES는 이를 거부하지 않고 동적으로 매핑해서 저장한다.
1-2. REST API와 CRUD
ES는 SQL 대신 REST API를 쓴다.
| 작업 (CRUD) | HTTP Method | RDBMS 대응 | 설명 |
|---|---|---|---|
| Create (생성) | POST | INSERT | 데이터를 인덱스에 저장 |
| Read (조회) | GET | SELECT | 저장된 데이터 검색 |
| Update (수정) | PUT | UPDATE | 데이터 수정 (전체 덮어쓰기) |
| Delete (삭제) | DELETE | DELETE | 데이터 삭제 |
대량 저장은 한 건씩 보내는 것보다 _bulk API로 묶어서 한 번에 처리하는 게 훨씬 빠르다.
1-3. 역색인 (Inverted Index)
ES가 방대한 데이터 안에서도 순식간에 검색 결과를 찾아내는 비결은 역색인(Inverted Index) 구조에 있다.
- 정색인(Forward Index): "1번 문서에는 '사과, 배'가 있다." (일반적인 DB 방식)
- 역색인(Inverted Index): "'사과'는 1, 3번 문서에 있다." (Elasticsearch 방식)
(▲ 데이터를 저장할 때 문장을 단어(Term) 단위로 쪼개어 매핑 테이블을 만든다.)
2. Kibana Query Language (KQL)
Kibana의 Discover 탭에서 데이터를 찾을 때 쓰는 쿼리 언어다.
예제 시나리오
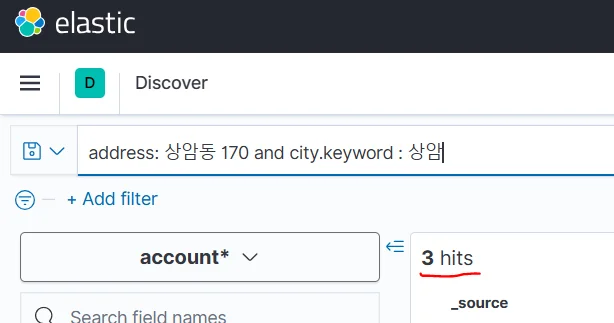
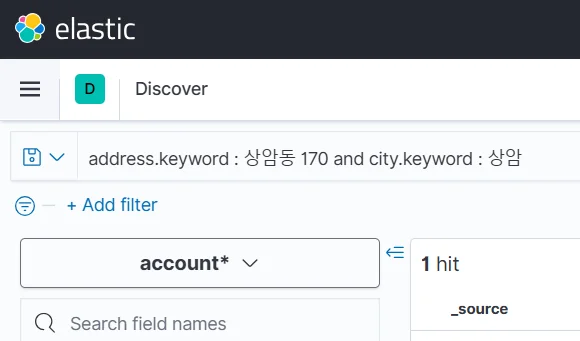
주소가 "상암동 170"이면서, 도시명이 "상암"인 데이터를 찾고 싶을 때
address: "상암동 170" and city.keyword: "상암"

KQL 핵심 규칙
- Text vs Keyword
- 일반 필드(Text): 분석기가 문장을 쪼개서 저장한다. 부분 일치 검색에 유리하다.
keyword필드: 원문 그대로 저장된다. 완전 일치 검색에 쓴다.
- Phrase 검색 (
"")
- 큰따옴표로 감싸면 띄어쓰기까지 포함된 하나의 덩어리로 인식한다.
기본적으로 대소문자를 구분하지 않는다. 구분이 필요하면 분석기(Analyzer) 를 직접 정의해서 인덱스를 만들어야 한다.
3. 데이터 파이프라인: Filebeat & Logstash
로그 데이터를 수집(Filebeat) → 가공(Logstash) → 적재(ES) 하는 파이프라인을 직접 구성해봤다.
3-1. 아키텍처 흐름
Filebeat (수집) ➡ Logstash (필터링/가공) ➡ Elasticsearch (적재)
Filebeat에서 ES로 바로 쏠 수도 있다. 근데 그러면 비정형 데이터가 정제 없이 그대로 들어간다. Logstash를 중간에 두면 불필요한 필드를 제거하거나 포맷을 통일할 수 있다.
3-2. 설정 및 실행 (Windows)
1) Filebeat 설정 (filebeat.yml).
실습에 필요한 Filebeat와 Logstash의 이전 버전은 아래 공식 링크에서 다운로드할 수 있다.
다운로드 :::
Filebeat가 ES가 아닌 Logstash로 보내도록 설정한다.
- filebeat.yml 수정
1. Filebeat inputs - paths 수정
2. ElasticSearch Output - 주석 처리
3. Logstash Output - 주석 해제
주의 사항 : output은 ES or Logstash 중 하나만 열어 놓고 해야 함 (충돌 가능성)
# Filebeat Inputs
filebeat.inputs:
- type: log
enabled: true
paths:
- C:\logs\*.log # 로그 파일 경로
# 1. ES 출력 주석 처리 (충돌 방지)
# output.elasticsearch:
# hosts: ["localhost:9200"]
# 2. Logstash 출력 활성화
output.logstash:
hosts: ["localhost:5044"]
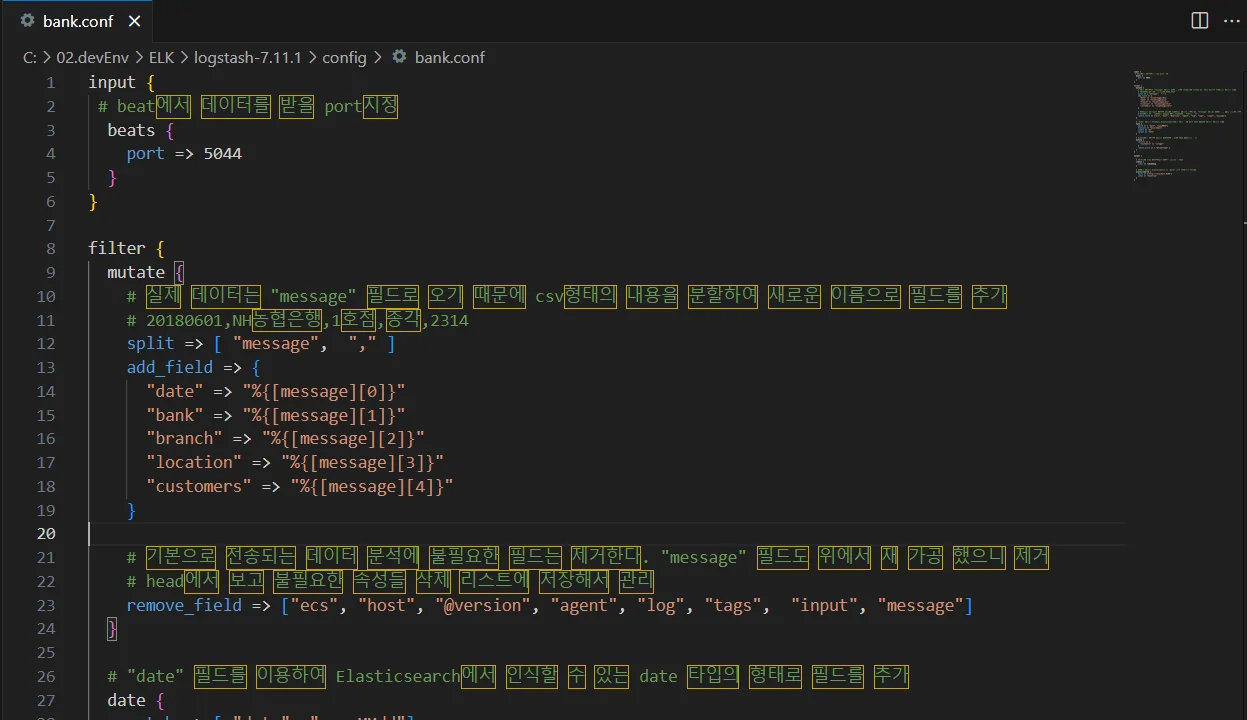
2) Logstash 파이프라인 설정 (bank.conf)
config 폴더 안에 .conf 파일을 만든다.
3) 실행 명령
Step 1. Logstash 실행 환경변수 설정 후 config 파일을 로드해서 실행한다.
# 환경변수 설정 (Windows 예시)
set JAVA_HOME="C:\02.devEnv\ELK\logstash-7.11.1\jdk"
setx PATH "%PATH%;%JAVA_HOME%\bin"
# Logstash 실행
logstash -f ..\config\bank.conf
Step 2. Filebeat 실행
filebeat -e -c filebeat.yml
Step 3. 결과 확인
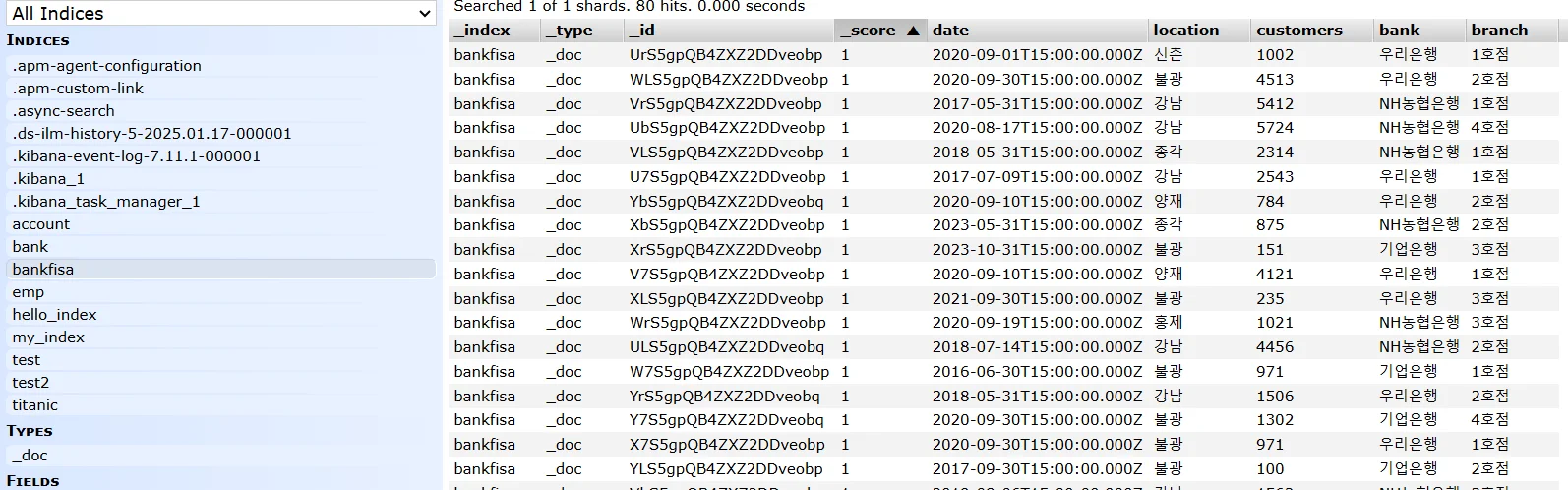
Elasticsearch-head 또는 Kibana Dev Tools에서 bank-data 인덱스가 생성됐는지 확인한다.
Other) Logstash 없이 Filebeat로만 처리 했을 경우?
- filebeat.yml 수정
1. ElasticSearch Output - 주석 해제
2. Logstash Output - 주석 처리
주의 사항 : output은 ES or Logstash 중 하나만 열어 놓고 해야 함 (충돌 가능성)
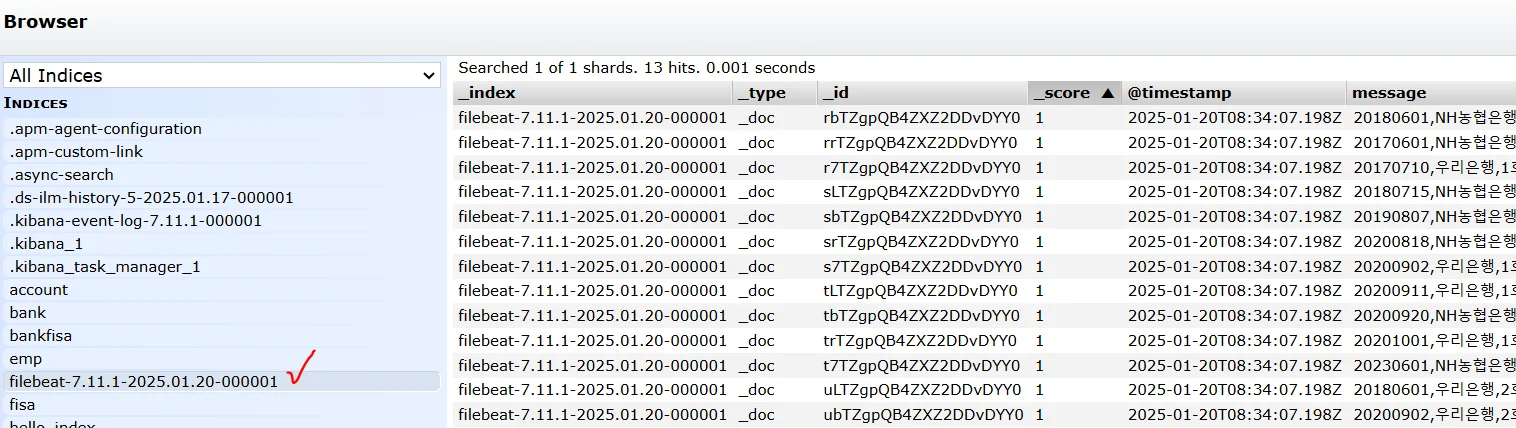
→ 정상적으로 생성은 되나 logstash config에서 세팅을 해주지 않은 파일이 올라가기 때문에 정형화 되지 않은 값들이 올라감 Logstash 전처리를 거쳐야 비정형 로그가 분석 가능한 형태로 바뀐다!!