DB를 쪼개야 하는 이유
팀 세미나 발표를 준비하면서 PostgreSQL + Citus로 샤딩과 레플리케이션을 직접 구성해봤다. 개념만 아는 것과 실제로 노드를 여러 개 띄워서 쿼리 성능을 비교해보는 건 체감이 다르다.
1. 분산 데이터베이스 개요
1.1 분산 데이터베이스(DDB)란?
데이터를 여러 노드에 나눠서 저장하는 방식이다. 트래픽이 몰려서 단일 DB 서버로 감당이 안 될 때, 용량이 한계에 다다랐을 때 선택한다.
1.2 CAP 이론
분산 시스템의 핵심 원칙으로, 다음 세 가지를 동시에 모두 만족할 수는 없다는 이론이다.
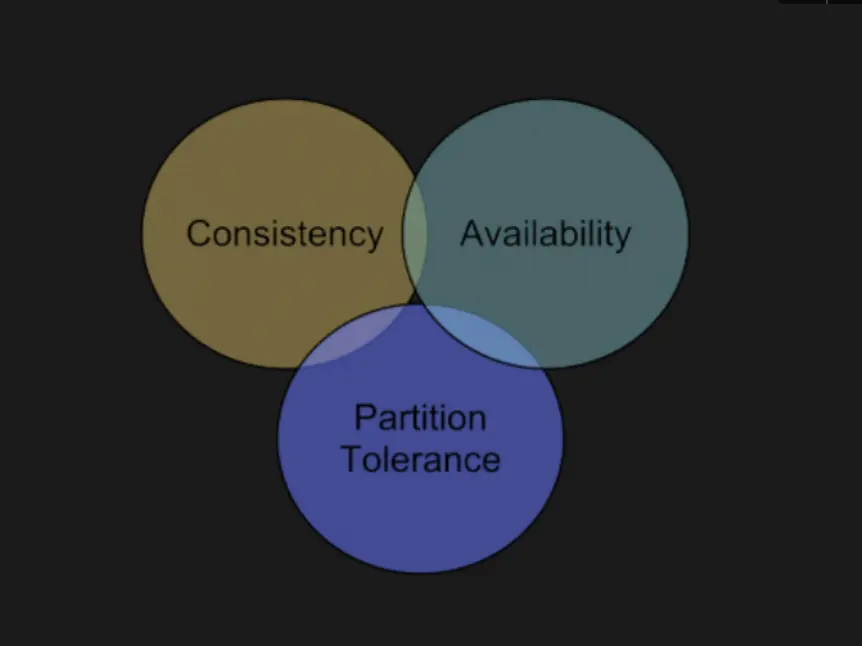
- Consistency (일관성): 모든 노드가 같은 시간에 같은 데이터를 보여줘야 한다.
- Availability (가용성): 일부 노드에 장애가 생겨도 서비스는 계속되어야 한다.
- Partition Tolerance (분할 허용성): 네트워크 단절이 발생해도 시스템은 동작해야 한다.
분산 환경에서 네트워크 장애는 피할 수 없다. P(분할 허용성) 는 기본으로 안고 가고, 시스템 목적에 따라 CP 또는 AP 중 하나를 선택한다.
2. 샤딩 (Sharding)
2.1 샤딩이란
한 서버로 감당이 안 되는 데이터를 여러 DB 서버(샤드)에 나눠서 저장하는 기술이다.
쿼리가 특정 샤드로만 라우팅되니 불필요한 노드 탐색이 줄어들고, 특정 샤드에 장애가 나도 나머지는 계속 돌아간다.
2.2 샤딩의 종류
-
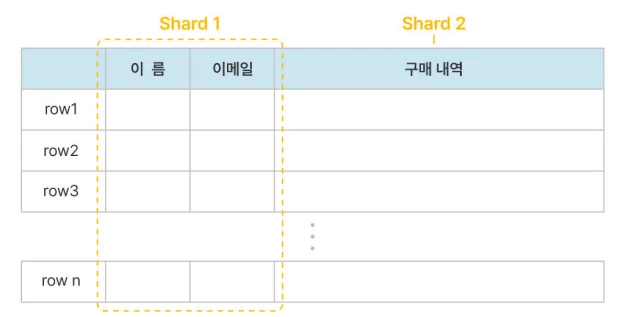
수직 샤딩 (Vertical): '사용자 DB', '주문 DB'처럼 기능이나 컬럼을 기준으로 쪼개는 방식.
-
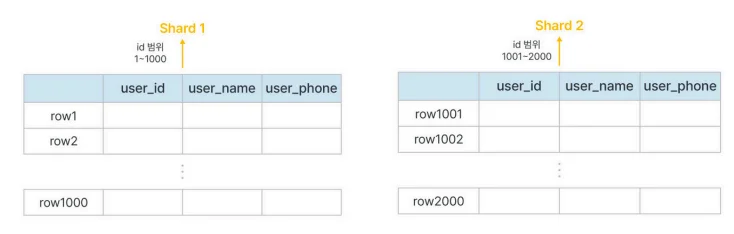
수평 샤딩 (Horizontal): 같은 테이블 스키마를 가지지만, 데이터 행(Row)을 샤딩 키 기준으로 나누는 방식.
3. 레플리케이션 (Replication)
- 성능 향상: DB 요청의 60~80% 정도가 읽기 작업이기 때문에 Replication만으로도 성능 대폭 향상 가능
- 지연시간 감소: 비동기 방식으로 운영되어 지연시간이 거의 없음
- Failover: 일부 노드에 장애가 발생하더라도 서비스 접근 보장
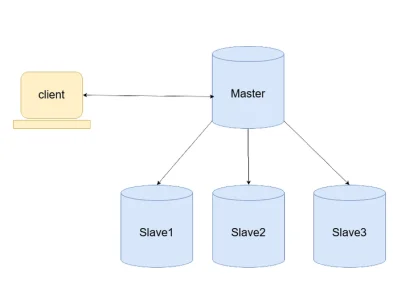
3.1 레플리케이션이란
동일한 데이터를 여러 노드에 복제하는 방식이다. 주로 Master-Slave 구조로 구성한다.
- Master: 쓰기(Write) 트래픽 전담
- Slave: 읽기(Read) 트래픽 전담 (부하 분산 효과)
3.2 동작 원리 및 페일오버 (Failover)
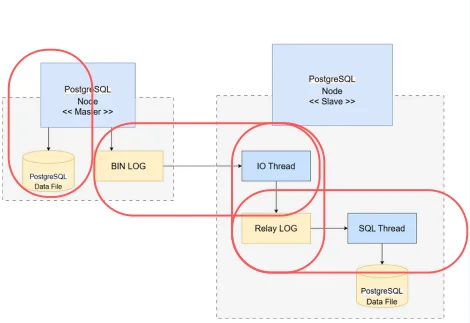
Master 노드에 변경이 생기면 로그를 생성하고, Slave 노드가 이를 가져와 반영한다.
Master 노드가 죽으면 Replication만으로는 안 된다. 자동화된 툴로 Slave 중 하나를 새 Master로 승격시켜야 서비스 중단 없이 버틸 수 있다.
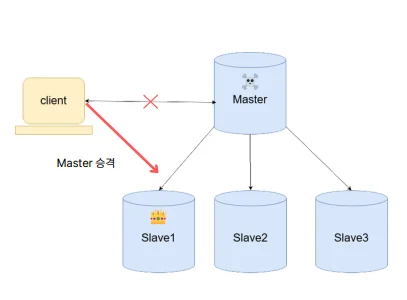
4. Sharding 구현 및 테스트
구현은 Docker 환경에서 PostgreSQL과 Citus를 활용해 실제 성능 차이를 검증했다.
구현 목표 : PostgreSQL과 Citus 기반 샤딩 환경에서 데이터 조회 성능을 비교하여, 샤딩이 특정 쿼리 성능에 미치는 영향을 분석함. 이를 위해 샤딩된 테이블과 일반 테이블 간의 조건을 동등하게 하고 성능을 공정하게 비교.
4.1 아키텍처 (Architecture)
테스트를 위해 Docker Container를 사용하여 다음과 같은 가상 분산 환경을 구성했다.
- Coordinator: 포트 5432 (애플리케이션 엔드포인트)
- Worker 1: 포트 5433 (데이터 저장소 1)
- Worker 2: 포트 5435 (데이터 저장소 2)
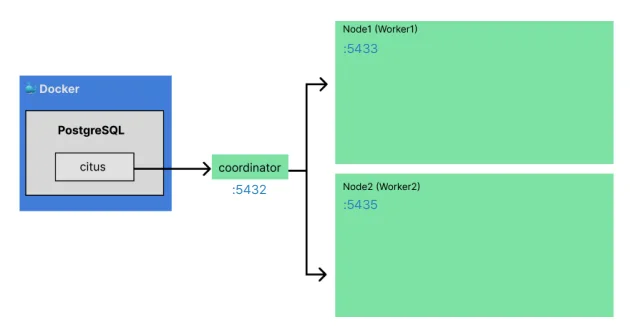
4.2 구현 방향
- 데이터 준비:
user_data테이블을 생성하고 100만 개의 더미 데이터를 INSERT 한다. - 샤딩 적용:
user_id를 Shard Key로 설정하여 데이터를 분산한다. - 검증: 일반 테이블과 샤딩 테이블에서 동일한
SELECT쿼리를 실행하여 Cost와 Execution Time을 비교한다.
4.3 단계별 구축 과정
1) Citus 활성화 및 Worker 노드 추가
PostgreSQL에 Citus 익스텐션을 활성화하고 Worker 노드 2개를 클러스터에 추가한다.
-- Citus Extension 활성화
CREATE EXTENSION citus;
-- Worker 노드 등록 (Docker 컨테이너 호스트명/포트 기준)
SELECT citus_add_node('worker-1', 5432);
SELECT citus_add_node('worker-2', 5432);
2) Worker 노드 정상 등록 확인
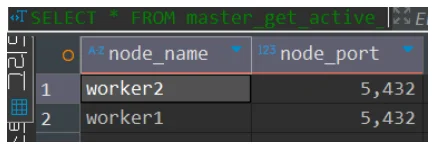
citus_get_active_worker_nodes() 함수로 노드들이 Coordinator와 정상 통신하는지 확인한다.
SELECT * FROM master_get_active_worker_nodes();
-- 결과: worker-1, worker-2 가 정상 출력됨을 확인
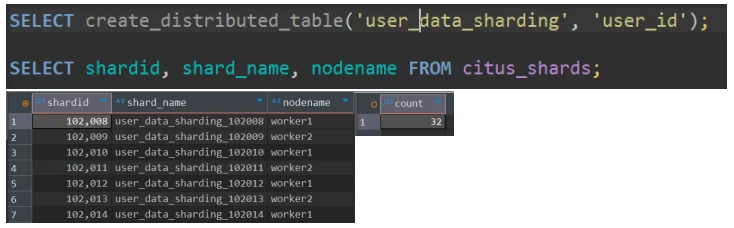
3) 테이블 샤딩 (Sharding)
user_data 테이블을 user_id 기준으로 32개 샤드로 분할한다.
-- 테이블 생성
CREATE TABLE user_data_sharding (...);
-- user_id를 기준으로 분산 테이블 생성 (Shard Count: 32)
SELECT create_distributed_table('user_data_sharding', 'user_id');
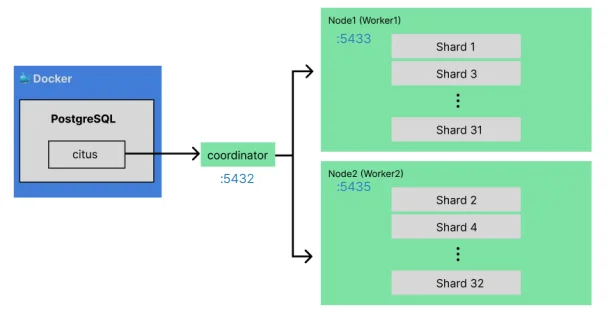
4) Round Robin 배치 확인
샤딩이 완료되면 32개 샤드가 2개 Worker 노드에 Round Robin으로 배포된다.
- Worker 1: Shard 1, 3, 5 ... (홀수 샤드)
- Worker 2: Shard 2, 4, 6 ... (짝수 샤드)
- 각 노드에 16개씩 균등 배치된다.
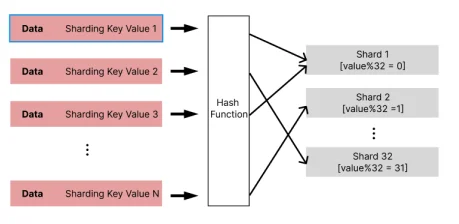
5) Deep Dive: 해시 샤딩과 데이터 분배 원리
해시 샤딩은 데이터가 특정 샤드에 몰리는 것(Data Skew)을 막기 위해 결정적(Deterministic) 해시 알고리즘을 쓴다. Coordinator가 키를 해싱해서 어느 노드로 보낼지 계산한다.
user_id = 1000이 들어왔을 때 Citus가 하는 일:
- 해싱:
Hash(1000) → 12345 - 모듈러:
12345 % 32 = 25 - 라우팅: 25번 샤드가 있는 노드로 쿼리 전송
4.4 성능 비교
동일한 조건(100만 건 데이터)에서 일반 테이블과 샤딩 테이블에 대해 특정 사용자를 조회하는 쿼리를 실행했다.
쿼리 (Query):
EXPLAIN ANALYZE
SELECT * FROM user_data WHERE user_id = 'user_123';
테스트 결과:
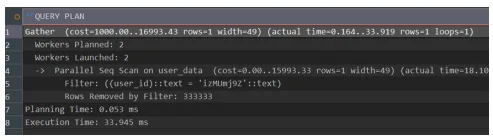
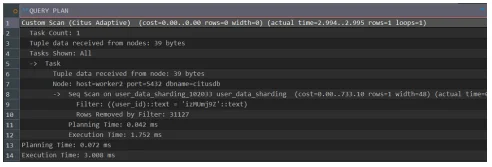
| 구분 | Execution Time | 결과 분석 |
|---|---|---|
| 일반 테이블 | 33.945 ms | 전체 데이터를 스캔(Full Scan)하거나 인덱스를 타더라도 단일 노드 부하 발생 |
| 샤딩 테이블 | 3.008 ms | 약 10배 성능 향상 |
분석: 해시 샤딩(Hash Sharding)을 적용했기 때문에, Coordinator가
user_id를 해싱하여 데이터가 저장된 특정 샤드(노드)로만 쿼리를 라우팅한다. 불필요한 노드 탐색이 제거되어 비약적인 성능 향상이 가능했다.
5. Sharding + Replication
단순한 샤딩은 성능을 높여주지만, 노드 하나가 죽으면 데이터 일부가 유실되는 위험이 있다. 이를 보완하기 위해 Citus 샤딩 환경에 Streaming Replication을 결합하여 고가용성(HA) 아키텍처를 구축했다.
5.1 샤딩 + 레플리케이션 목표
- 성능: 2개의 Worker 노드로 읽기/쓰기 분산 (Sharding)
- 안정성: 각 Worker 노드마다 1개의 Slave 노드를 붙여 실시간 복제 (Replication)
- 결과: Master 노드 장애 시에도 Slave 노드를 통해 서비스 지속
5.2 아키텍처
각 Worker 노드(Master) 뒤에 동일한 데이터를 가진 Slave 노드를 배치하여 총 5개의 컨테이너로 구성했다.
- Coordinator: 쿼리 라우팅
- Worker 1 (Master) ⇌ Worker 1 (Slave): 데이터 동기화
- Worker 2 (Master) ⇌ Worker 2 (Slave): 데이터 동기화
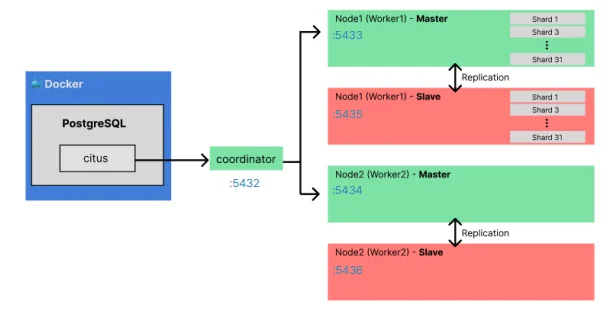
5.3 환경 구성: Citus 활성화 및 노드 추가
앞의 샤딩 실습과 동일하게 Citus를 활성화하고, 이번엔 복제 구성을 고려해서 Worker 노드를 추가한다.
-- 1. Citus Extension 활성화 (모든 노드)
CREATE EXTENSION citus;
-- 2. Worker 노드(Master) 2개 추가
SELECT citus_add_node('worker-1-master', 5432);
SELECT citus_add_node('worker-2-master', 5432);
5.4 테이블 샤딩 (Sharding)
테이블을 만들고 user_id 기준으로 분산한다.
-- 테이블 생성 및 샤딩 적용
CREATE TABLE user_data_ha (...);
SELECT create_distributed_table('user_data_ha', 'user_id');
정상 실행되면 32개 샤드가 두 Master 노드에 분산 저장된다.
5.5 Streaming Replication 적용 및 확인
PostgreSQL의 기본 기능인 Streaming Replication을 설정하여 Master와 Slave를 연결했다.
연결 후 pg_stat_wal_receiver 뷰로 복제 상태를 확인한다.
-- Slave 노드에서 복제 상태 확인 쿼리
SELECT status, sender_host, slot_name
FROM pg_stat_wal_receiver;

- status:
streaming상태여야 정상적으로 실시간 복제가 이루어지고 있는 것이다. - sender_host: Slave가 바라보고 있는 Master 노드의 주소가 정확한지 확인한다.
5.6 데이터 동기화 검증 (Data Sync)
Master에 데이터가 들어갔을 때 Slave에도 즉시 반영되는지 확인한다.
- Master:
INSERT INTO user_data_ha ... - Slave:
SELECT * FROM user_data_ha ...
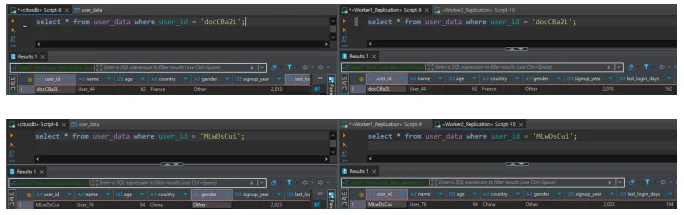
결과: Slave 노드는 Read-Only 모드임에도 불구하고, Master와 완벽하게 동일한 데이터를 보유하고 있음을 확인했다. 자신이 복제한 Master 노드의 샤드 데이터만 정확히 가지고 있다.
5.7 장애 대응 (Failover)
가장 핵심적인 네트워크 장애 상황을 시뮬레이션했다.
상황: Worker 1번의 Master 노드 네트워크를 강제로 차단하여 다운시킴. 기대 결과: 서비스 중단 없이 Slave 노드를 통해 데이터를 읽어올 수 있어야 함.
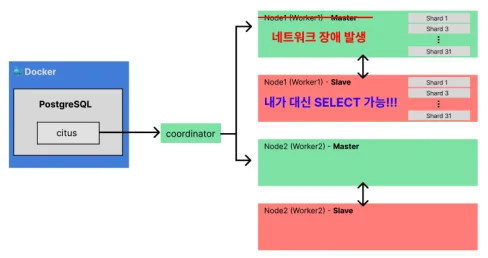
검증 결과: 기존에는 Master가 죽으면 쿼리 자체가 실패했으나, 레플리케이션 구성 후에는 Slave 노드에서 정상적으로 SELECT 쿼리가 수행되었다.
결론: 샤딩을 통해 성능을 확보하고, 레플리케이션을 통해 SPOF(단일 장애점) 문제를 해결하여 고가용성 분산 데이터베이스 환경을 성공적으로 구축했다.
6. 비교 분석
| 특징 | 샤딩 (Sharding) | 레플리케이션 (Replication) |
|---|---|---|
| 핵심 목적 | 확장성 (Scalability) | 가용성 (Availability) |
| 데이터 형태 | 데이터를 조각내어 분산 저장 | 데이터를 통째로 복제하여 저장 |
| 장점 | 쓰기/읽기 부하 분산, 대용량 처리 | 읽기 성능 향상, 장애 시 데이터 보존 |
| 단점 | 관리 복잡도 증가, JOIN 연산 어려움 | 데이터 동기화 지연(Lag) 발생 가능 |
샤딩은 쓰기/읽기 부하를 분산하고, 레플리케이션은 노드가 죽어도 서비스가 버티게 한다. 둘은 서로 다른 문제를 푼다. 대규모 트래픽을 감당하면서 고가용성까지 필요하다면 같이 써야 한다.