NoSQL 톺아보기
오늘 사이드 프로젝트에 MongoDB를 연동하는 작업을 진행하면서 그동안 익숙하게 사용해왔던 RDBMS와는 전혀 다른 NoSQL 진영의 데이터베이스를 다루었다.
수많은 트러블슈팅 해결(특히 환경 설정과 유효성 검사 문제) 끝에 데이터를 성공적으로 적재하고 조회하는 데 성공했지만 그 과정에서 든 근본적인 의문이 있었다.
대체 테이블도 없고 스키마 강제도 안하는 이 불안한 DB를 왜 쓰는 걸까? 또 언제 써야 유리할까?
RDBMS vs NoSQL (Document DB)
본격적으로 몽고디비를 파헤치기 전에 내가 알던 SQL과 NoSQL 중 하나인 문서 지향 DB의 특징을 비교해봤다.
| 특징 | RDBMS (MySQL, PostgreSQL 등) | NoSQL (MongoDB 기준) |
|---|---|---|
| 데이터 모델 | 엄격한 테이블 구조 (정규화) | 유연한 문서 구조 (비정규화) |
| 스키마 | 고정된 스키마 (미리 정의 필수) | 동적 스키마 (데이터마다 다름) |
| 확장성 | 수직 확장 (Scale-up, 고사양 서버) | 수평 확장 (Scale-out, 저가 서버 분산) |
| 조인(Join) | 매우 강력하고 효율적임 | 가급적 피함 (내장 구조 선호) |
| 트랜잭션 | 강력한 ACID 보장 | 단일 문서 수준의 원자성 위주 |
1. 테이블은 어디에?
RDBMS에서 데이터베이스의 기본은 테이블이다. 엑셀 시트처럼 행과 열이 딱 맞춰져 있어야 마음이 편하다. 하지만 MongoDB는 테이블이 아닌 Collection이라는 개념을 가지고 있었다.
그 안에는 정형화된 행 대신 자유분방한 JSON(BSON) 구조의 문서들이 이루어져 있었다.
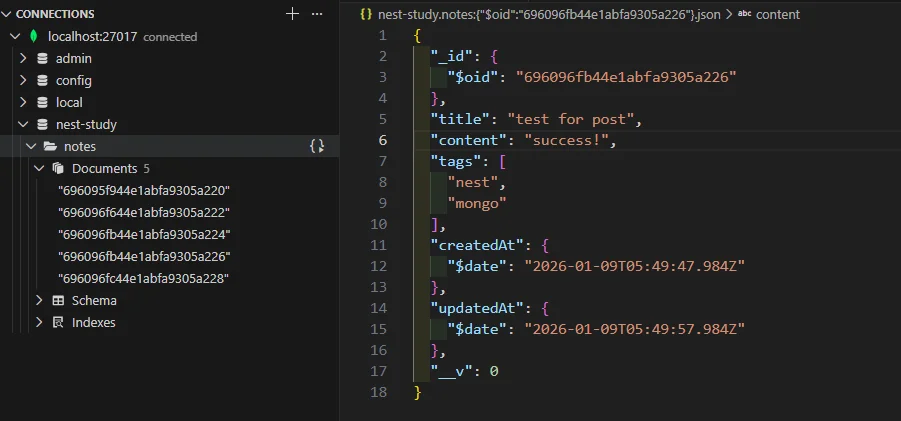
하나의 컬렉션 안에 어떤 문서는 tags 필드가 있고 어떤 문서는 없는 상황이 아무렇지 않게 허용된다. NoSQL의 여러 갈래 중에서도 문서 지향 DB가 가지는 전형적인 특징이다.
2. "Schema-less"의 진짜 의미
MongoDB를 포함한 많은 NoSQL의 가장 큰 특징은 'Schema-less'다. 하지만 오늘 경험해 보니 이 말은 틀렸다. 정확히는 "DB 엔진 레벨에서 스키마를 강제하지 않는다" 는 뜻이었다.
RDBMS는 데이터의 파수꾼이다. VARCHAR(10) 컬럼에 숫자를 넣거나 11글자를 넣으려 하면 DB가 에러를 뱉으며 막아주지만, 몽고디비 같은 도구들은 기본적으로 주는 대로 모두 다 받는다.
자유로우니 무조건 유리하다?
이 개념을 보자마자 이 자유로움은 양날의 검이라 생각했다.
-
장점 (개발 속도): 기획이 바뀌어서 필드를 추가해야 할 때, 골치 아픈
ALTER TABLE마이그레이션 없이 그냥 코드만 수정해서 배포하면 된다. 초기 스타트업이나 애자일 환경에서는 엄청난 생산성이다! -
단점 (데이터 정합성 위기): 실수로 GUI 툴에서 데이터를 수정하다가
title필드를titl로 오타를 내서 저장했다고 치자. RDBMS는 에러를 내겠지만 MongoDB는titl이라는 새로운 필드로 인식하고 조용히 저장한다. 나중에 애플리케이션은title이 없어서 에러를 뿜어내거나 원하는 데이터를 모두 못 불러올 가능성도 있다.
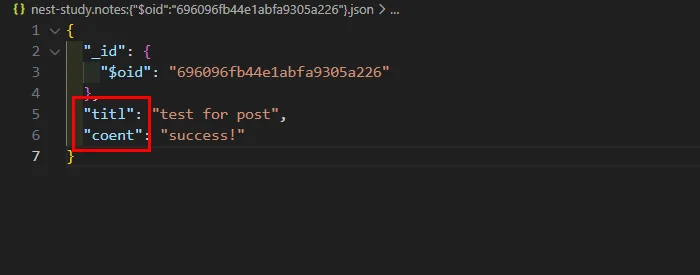
실수로 JSON이 수정되어 이상하게 저장되어도 별다른 validation이 없어 정상인 것처럼 저장되는 문제가 생길 수도 있다.
3. 책임은 백엔드에서
데이터를 검증하는 책임은 오롯이 백엔드가 짊어져야 한다. 오늘 NestJS에서 class-validator와 DTO 설정 때문에 고생했던 이유가 바로 이것이었다.
뭔가 안전장치가 있을 거라 생각해서 찾아봤다.
NestJS 환경에서는 보통 3중 방어선을 구축해서 RDBMS 수준의 안전성을 확보하려 노력한다.
- DTO + ValidationPipe: API 요청이 들어오는 입구에서 타입을 검사한다.
- Mongoose Schema: 코드가 DB에 데이터를 쓰기 직전에 필수 값이나 기본값을 최종 확인한다.
- TypeScript: 개발 단계에서 컴파일 에러로 오타를 잡아낸다.
몽고디비 같은 NoSQL을 쓰면 DB 관리는 유연해지는 대신 백엔드 코드의 복잡도는 올라간다.
4. ACID의 부재
RDBMS를 쓰던 개발자가 NoSQL을 쓸 때 가장 불안한 지점이 바로 트랜잭션일 것이다.
RDBMS는 여러 테이블에 걸쳐 데이터를 수정할 때 하나라도 실패하면 전체를 되돌리는 ACID 트랜잭션이 기본이다. 하지만 몽고디비는 태생적으로 단일 문서에 대한 원자성만을 보장하는 데 최적화되어 있다.
물론 4.0 버전 이후로 다중 문서 트랜잭션을 지원하긴 하지만 RDBMS에 비하면 성능 오버헤드가 크고 복잡하다. 금융 시스템처럼 돈이 오가는 정밀한 작업에서 몽고디비를 주저하는 결정적인 이유가 여기에 있다.
결국 몽고디비에서 트랜잭션이 자주 필요해진다면, 데이터를 내장하지 않고 쪼개놨을 확률이 높다.
5. 성능과 용량의 냉정한 트레이드오프
"그래서 성능은 좋은가?"라는 질문에 대한 답은 "설계하기 나름"이다.
용량은?
RDBMS는 컬럼명을 헤더에 한 번만 정의하지만 MongoDB는 모든 문서마다 키 이름을 반복해서 저장한다. ({"title": "A"}, {"title": "B"} ...) 데이터가 1억 건이면 "title"이라는 글자도 1억 번 저장된다...
논리적으로는 엄청난 용량 낭비지만 MongoDB는 이를 WiredTiger라는 압축 엔진으로 상쇄한다. 스토리지는 싸고 성능은 비싸다는 현대 인프라 논리에서 보면 실용적인 트레이드오프다.
JOIN을 포기하고 속도에 집중
문서 지향 NoSQL 성능의 핵심은 "Embedding(내장)" 이다. RDBMS가 정규화를 통해 데이터를 쪼개고 JOIN으로 합친다면 MongoDB는 관련된 데이터를 하나의 문서에 다 때려 넣는 걸 권장한다.
JOIN 연산을 피하고 한 번의 I/O로 필요한 모든 데이터를 가져오는 것, 이것이 대용량 트래픽 환경에서 NoSQL이 RDBMS를 압도하는 이유다. 반대로 NoSQL에서 RDBMS처럼 설계하고 $lookup(조인)을 남발하면 최악의 성능을 보게 된다.
마치며
NoSQL은 결코 RDBMS보다 쉽지 않다. 오히려 자유도가 높은 만큼 개발자가 신경 써야 할 아키텍처와 코드 레벨의 방어 로직은 더 많아진다.
결제나 금융처럼 데이터의 무결성이 목숨보다 중요한 곳에는 여전히 RDBMS가 정답이다. 하지만 빠르게 변하는 요구사항과 예측하기 어려운 트래픽을 감당해야 하는 서비스에서 MongoDB 같은 NoSQL은 분명히 강점이 있다.
자유도가 높은 만큼 그 책임은 개발자 몫이다.